
word auto complete¶
- 염문자 4개를 학습시켜 3글자만 주어지면 나머지 한 글자를 추처하여 단어를 완성
- dynamic_rnn의 sequence_length 옵션을 사용하면 가변 길이 단어를 학습시킬 수 있음
- 짧은 단어는 가장 긴 단어의 길이 만큼 뒷부분을 0으로 채우고, 해당 단어의 길이를 계산해 (batch_size)만큼의 배열로 sequence_length로 넘겨주면 됨
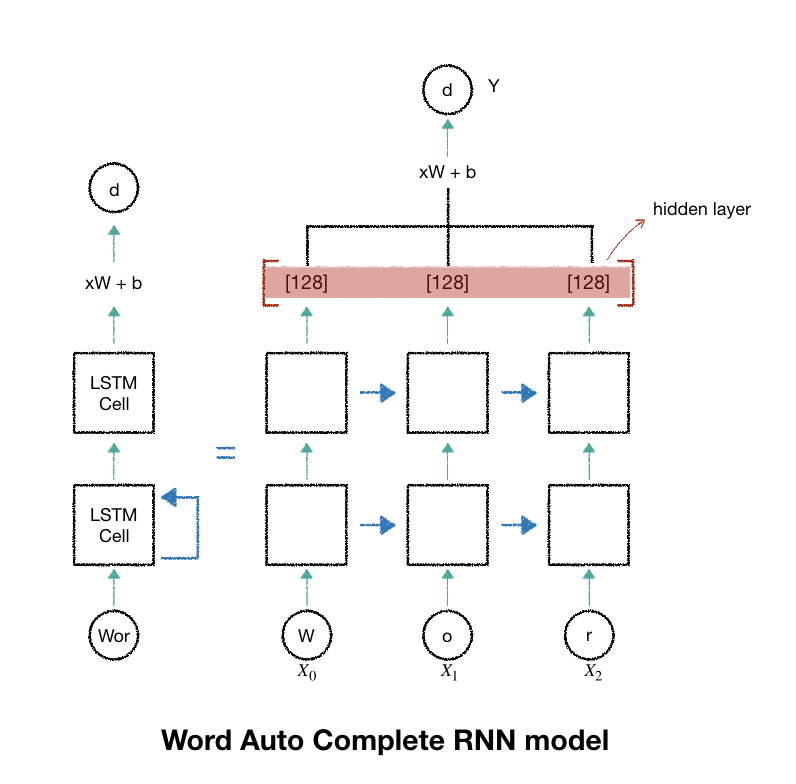
- 학습시킬 데이터는 영문자로 구성된 임의의 단어를 사용할 것이고, 한 글자 한글자를 하나의 단계로 봄
- 한글자가 한 단계의 입력값이 되고, 총 글자 수가 전체 단계가 됨
- 입력으로는 알파벳 순서에서 각 글자에 해당하는 인덱스를 one-hot encoding으로 표현한 값을 취함
In [1]:
import tensorflow as tf
import numpy as np
In [2]:
char_arr = ["a", "b", "c", "d", "e", "f", "g",
"h", "i", "j", "k", "l", "m", "n",
"o", "p", "q", "r", "s", "t", "u",
"v", "w", "x", "y", "z"]
num_dic = {n: i for i, n in enumerate(char_arr)}
dic_len = len(num_dic)
In [3]:
seq_data = ["word", "wood", "deep", "dive", "cold", "cool", "load", "love", "kiss", "kind"]
utiliy function¶
- "deep"는 입력으로 "d", "e", "e"를 취하고, 각 알파벳의 인덱스를 구해 배열로 만들면 [3, 4, 4]가 됨
- 이를 one-hot encoding
In [4]:
def make_batch(seq_data):
input_batch = []
target_batch = []
for seq in seq_data:
input = [num_dic[n] for n in seq[:-1]]
target = num_dic[seq[-1]]
input_batch.append(np.eye(dic_len)[input])
target_batch.append(target)
return input_batch, target_batch
hyper parameter setting¶
- 단어의 전체중 처음 3글자를 단계적으로 학습할 것이므로 n_step=3
- 입력값과 출력값은 one-hot encoding을 사용하므로 dic_len과 같음
- sparse_softmax_cross_entropy_with_logits 함수를 사용하더라도 예측 모델의 출력값은 one-hot encoding을 해야함
- sparse_softmax_cross_entropy_with_logits 함수를 사용할 때 실측값인 labels의 값은 인덱스의 숫자를 그대로 사용하고, 예측 모델의 출력값은 인덱스의 one-hot encoding을 사용
In [5]:
learning_rate = 0.001
n_hidden = 128
total_epoch = 10000
n_step = 3
n_input = n_class = dic_len
In [6]:
X = tf.placeholder(tf.float32, [None, n_step, n_input], name="input_X")
Y = tf.placeholder(tf.int32, [None])
W = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
In [7]:
cell1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
cell1 = tf.nn.rnn_cell.DropoutWrapper(cell1, output_keep_prob=0.5)
cell2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
# MultiRNNCell 함수를 사용하여 조합
multi_cell = tf.nn.rnn_cell.MultiRNNCell([cell1, cell2])
outputs, states = tf.nn.dynamic_rnn(multi_cell, X, dtype=tf.float32)
In [8]:
outputs = tf.transpose(outputs, [1, 0, 2])
outputs = outputs[-1]
model = tf.matmul(outputs, W) + b
modeling¶
In [9]:
cost = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model, labels=Y)
)
opt = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
In [10]:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
input_batch, output_batch = make_batch(seq_data)
cost_epoch = []
for epoch in range(total_epoch):
_, loss = sess.run([opt, cost], feed_dict={X: input_batch, Y: output_batch})
cost_epoch.append(loss)
if (epoch+1) % 2000 ==0:
print("Epoch: {}, cost= {}".format(epoch+1, loss))
print("\noptimization complete")
In [16]:
import matplotlib.pyplot as plt
plt.rcParams["axes.unicode_minus"] = False
plt.figure(figsize=(20,6))
plt.title("cost")
plt.plot(cost_epoch, linewidth=1)
plt.show()

- 실측값을 원-핫 인코딩이아닌 인덱스를 그대로 사용
In [12]:
prediction = tf.cast(tf.argmax(model, 1), tf.int32)
prediction_check = tf.equal(prediction, Y)
accuracy = tf.reduce_mean(tf.cast(prediction_check, tf.float32))
prediction¶
- prediction model
In [13]:
input_batch, target_batch = make_batch(seq_data)
predict, accuracy_val = sess.run([prediction, accuracy],
feed_dict={X: input_batch, Y: target_batch})
- predict
In [14]:
predict_word = []
for idx, val in enumerate(seq_data):
last_char = char_arr[predict[idx]]
predict_word.append(val[:3] + last_char)
print("\n==== prediction ====")
print("input_value: \t\t{}".format([w[:3] for w in seq_data]))
print("prediction_value: \t{}".format(predict_word))
print("accuracy: {:.3f}".format(accuracy_val))
In [15]:
from IPython.core.display import HTML, display
display(HTML("<style> .container{width:100% !important;}</style>"))
'Deep_Learning' 카테고리의 다른 글
| 18.word2vec (0) | 2018.12.19 |
|---|---|
| 17.seq2seq (0) | 2018.12.19 |
| 15.RNN_mnist (1) | 2018.12.18 |
| 14.gan (0) | 2018.12.16 |
| 13.auto-encoder (0) | 2018.12.15 |