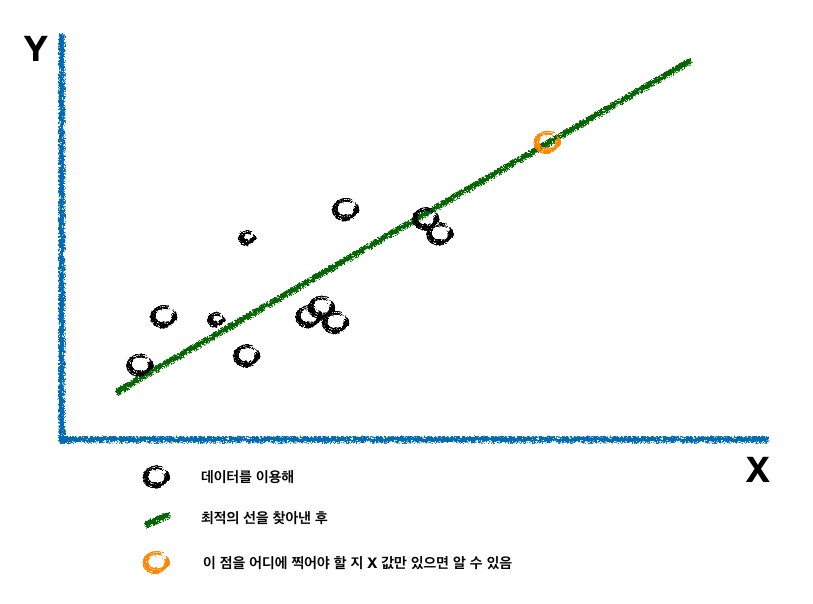
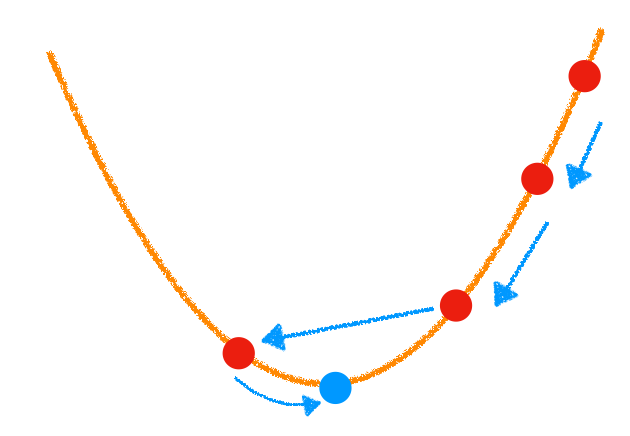
review¶
In [1]:
import tensorflow as tf
import numpy as np
In [2]:
# data_define
# data_define
# [털, 날개]
x_data = np.array([
[0, 0],
[1, 0],
[1, 1],
[0, 0],
[0, 0],
[0, 1]
])
# [기타, 포유류, 조류]
y_data = np.array([
[1, 0, 0], # 기타
[0, 1, 0], # 포유류
[0, 0, 1], # 조류
[1, 0, 0], # 기타
[1, 0, 0], # 기타
[0, 0, 1] # 조류
])
model setting¶
In [3]:
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([2, 10], mean=0, stddev=1))
W2 = tf.Variable(tf.random_normal([10, 3], mean=0, stddev=1))
b1 = tf.Variable(tf.zeros([10]))
b2 = tf.Variable(tf.zeros([3]))
L1 = tf.add(tf.matmul(X, W1), b1)
L1 = tf.nn.sigmoid(L1)
model = tf.add(tf.matmul(L1, W2), b2)
model = tf.nn.softmax(model)
cost function¶
- one-hot encoding을 이용한 대부분의 모델에서는 cross-entropy를 사용
$E(w,\quad b)\quad =\quad -\sum _{ n=1 }^{ N } \left\{ { t_{ n }logy_{ n }+(1-t_{ n })log(1-y_{ n }) } \right\} $
In [4]:
cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
modeling¶
In [5]:
optimizier = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizier.minimize(cost)
In [6]:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for step in range(1000):
sess.run(train_op, feed_dict={X: x_data, Y:y_data})
if (step+1) % 50 == 0:
print("{}, {:.5f}".format(step+1, sess.run(cost, feed_dict={X: x_data, Y:y_data})))
output¶
In [7]:
sess.run(model, feed_dict={X: x_data, Y:y_data})
Out[7]:
In [8]:
prediction = tf.argmax(model, axis=1)
target = tf.argmax(Y, axis=1)
print("prediction: \t{}".format(sess.run(prediction, feed_dict={X:x_data})))
print("target: \t{}".format(sess.run(target, feed_dict={Y:y_data})))
accuracy¶
In [9]:
is_correct = tf.equal(prediction, target)
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print("accuracy: \t{:.3f}".format(sess.run(accuracy, feed_dict={X:x_data, Y:y_data})))
In [10]:
from IPython.core.display import display, HTML
display(HTML("<style> .container{width:100% !important;}</style>"))
'Deep_Learning' 카테고리의 다른 글
| 07.tensorboard02_example (0) | 2018.12.09 |
|---|---|
| 06.tensorboard01_example (0) | 2018.12.09 |
| 04.deep_neural_net_Costfun1 (0) | 2018.12.09 |
| 03.classification (0) | 2018.12.09 |
| 02.linear_regression (0) | 2018.12.09 |