word2vec¶
- 단어를 벡터화할 때 단어의 문맥적 의미를 보존
In [1]:
from konlpy.tag import Kkma
from konlpy.utils import pprint
from gensim.models.word2vec import Word2Vec
import warnings
warnings.filterwarnings("ignore")
- input data
- 네이버 기사 로드
In [2]:
data = [["KB금융지주가 KB증권, KB캐피탈, KB부동산신탁 등 3개 계열사 대표를 새로 선정했다. 가장 큰 관심이 쏠렸던 KB증권 대표이사 후보에는 박정림 KB증권 부사장 겸 KB국민은행 부행장을 선정했다. 박 후보가 주주총회 등을 거쳐 최종 선임되면 금융투자업계 최초 여성 최고경영자(CEO)가 등장한다. KB금융은 19일 계열사 대표이사후보 추천위원회(이하 대추위)를 열고 KB증권·KB캐피탈·KB부동산신탁 등 7개 계열사 대표 후보를 선정했다고 밝혔다. KB증권 신임 대표이사 후보에는 박정림 KB증권 부사장 겸 KB국민은행 부행장과 김성현 KB증권 부사장을 추천했다. KB증권은 기존의 복수 대표체제를 유지한다. KB캐피탈에는 황수남 KB캐피탈 전무, KB부동산신탁에는 김청겸 KB국민은행 영등포 지역영업그룹대표가 각각 대표이사 후보로 선정됐다. 양종희 KB손해보험 대표, 조재민·이현승 KB자산운용 대표, 김해경 KB신용정보 대표는 재선정됐다. KB데이타시스템은 이른 시일 내에 적합한 인사를 찾아 추후 추천할 계획이다. 박정림 부사장이 KB증권 대표에 취임하면 증권사 최초로 여성 CEO가 탄생한다. 박 후보는 KB금융지주에서 WM(자산관리)과 리스크, 여신 등 요직을 두루 거쳤다. 그룹 WM 부문 시너지영업을 이끌며 리더십을 발휘하고 있다는 점을 높게 평가 받는다. 김성현 부사장은 대표적인 투자은행(IB) 전문가다. 투자자산 다변화를 통해 시장 지위를 바꿀 수 있는 리더십을 갖췄다는 평가를 받는다. 신임 대표는 20∼21일 계열사 대표이사후보 추천위원회의 최종 심사와 추천을 거쳐 주주총회에서 확정할 계획이다. 신임 대표 임기는 2년, 재선정 대표 임기는 1년이다."],
["서울 여의도에서 ‘카카오 카풀’에 반대하는 전국 택시업계 관계자들이 20일 대규모 집회를 벌인다. 택시기사 최 모 씨의 분신 등을 계기로 업계가 ‘총력투쟁’을 예고한 가운데 집회‧시위 시간이 출‧퇴근 시간과 겹쳐 이 시각 여의도 주변에 극심한 교통체증이 예상된다. 19일 경찰과 택시업계 등에 따르면 20일 오후 2시 전국택시노동조합연맹, 전국민주택시노동조합연맹, 전국개인택시운송사업조합연합회 등 4개 단체가 서울 여의도 국회 앞 의사당대로에서 3차 집회를 연다. 강신표 전국택시노동조합연맹 위원장은 집회를 하루 앞두고 열린 기자회견에서 “죽든지 살든지 총력 투쟁을 할 것”이라고 말했다. ‘국회를 포위하겠다던 기존 계획은 그대로 진행되느냐’는 질문에 강 위원장은 “그렇다”면서도 “만약 (경찰이) 막으면 할 수 없겠지만, 하는 데까지 최선을 다해 적폐 1호인 국회를 반드시 심판할 것”이라고 강조했다. 강 위원장은 “내일은 제주도를 포함한 전국의 택시가 운행을 중지한다”며 “앞으로 4차, 5차 집회 일정이 잡히면 그 날마다 택시 운행이 정지될 것”이라고 말했다. 이어 “자꾸 시민에게 불편을 드려죄송하지만 생존권을 지키기 위해 여의도 국회 앞에 모일 수밖에 없는 절박한 상황을 헤아려 주시길 바란다”고 덧붙였다."],
["'내보험 찾아줌' 홈페이지가 접속자 폭주로 인해 접속 대기시간이 길어지고 있다. 19일 오후 9시20분 현재 '내보험 찾아줌' 홈페이지에는 접속자 수가 몰리며 서비스 이용이 불가능한 상태다. 현재 사이트 접속자 수는 4641여명에 달한다. 금감원에 따르면 11월 말 기준 소비자가 찾아가지 않은 숨은 보험금은 약 9조8130억원인 것으로 나타났다.지난해 12월부터 지난달까지 숨은보험금 찾아주기 안내 활동을 통해 약 3조125억원(240만5000건)이 주인을 찾았다. 업권별로는 생명보험회사가 약 2조7907억원(222만건), 손해보험회사가 2218억원(18만 5000건)을 찾아줬다. 금감원은 20일부터 기존 '내보험 찾아줌' 서비스를 개선해 찾은 숨은보험금을 각 보험회사 온라인 청구시스템에 바로 접속할 수있도록 링크를 제공한다고 밝혔다. 기존 숨은 보험금 청구 시에는 소비자가 개별적으로 해당 보험회사 홈페이지, 콜센터, 계약 유지·관리 담당 설계사 등을 찾아 별도로 진행해야 하는 불편이 있었다. 앞으로는 '내보험 찾아줌' 홈페이지에 접속해 이름, 휴대폰 번호, 주민등록번호를 입력 후 휴대폰 인증을 거치면 생명보험 25개사, 손해보험 16개사 등 모두 41개 보험회사를 대상으로 숨은 보험금을 조회할 수 있다. 숨은 보험금이 있는 경우 해당 보험사에 보험금 지급청구를 하면 영업일 3일 이내 금액을 지급한다. 단 이미 보험금을 청구해 심사 중이거나 지급정지 등으로 청구할 수 없는 보험금은 조회되지 않는다."],
["KB증권은 김성현 KB증권 IB총괄 부사장과 박정림 KB증권 WM 부문 부사장을 신임 대표로 각각 선임했다고 19일 밝혔다. 윤경은, 전병조 대표이사가 자리에서 물러났지만 각자 대표이사 체제는 유지된다. 이는 WM과 IB의 부문을 각각 집중하기 위함으로 풀이된다. 특히 박 신임 대표는 증권업계 첫 여성 최고경영자(CEO)이다. 박 신임 대표는 서울대 경영학과·경영대학원 출신으로 1986년 체이스맨해튼 서울지점, 조흥은행, 삼성화재 등을 거쳐 2004년 처음으로 KB국민은행에 들어왔다. 당시 시장운영리스크 부장을 시작으로 2012년엔 WM본부장, 2014년 리스크관리그룹 부행장, 2015년 KB금융지주 리스크관리책임자 부사장 겸 리스크관리그룹 부행장을 맡았고 2016년엔 여신그룹 부행장을 맡았다. 작년부턴 KB금융 WM총괄 부사장 겸 은행 WM그룹 부행장 겸 KB증권 WM부문 부사장을 맡고 있다. KB금융지주는 박 신임 대표에 대해 WM, 리스크, 여신 등 폭넓은 업무 경험을 바탕으로 수익 확대에 대한 실행역량을 보유하고 있다고 밝혔다. 그룹 WM 부문의 시너지영업을 진두지휘하며 리더십을 발휘했다는 평가다. 현 IB총괄 부사장인 김성현 신임 대표는 IB부문을 총괄한다. 김 신임 대표이사는 연세대 경제학과를 졸업하고 1988년 대신증권에 입사한 이후 한누리투자증권을 거쳐 2008년 KB투자증권 기업금융본부장으로 임명됐다. 이후 2015년부터 KB투자증권 IB부문에서 일한 전문가다. KB금융지주는 김 신임 대표에 대해 IB 전문가로 투자자산 다변화 등을 통해 시장 지위를 개선시킬 수 있는 검증된 리더십을 보유했다고 평가했다."],
["""서민금융진흥원은 지난 18일 서울 청계천로 본원에서 제2차 서민금융 전문가 간담회를 개최했다소 19일 밝혔다.
이번 간담회는 서민금융, 복지, 자활사업 등 각 분야 전문가들이 참석한 가운데, 정책서민금융 지원의 방향성에 대해서 의견을 청취하기 위해 마련됐다. 이날 이 원장은 "소득양극화와 고용부진 심화 등으로 서민·취약계층, 자영업자들의 경제적 어려움이 커지는 가운데 사회안전망으로서 서민금융의 역할이 중요한 시점"이라며, "현재 8등급 이하자가 263만명이고 이들중 74%가 연체중인 상황에서 정상적인 금융 이용이 어려운 취약계층에게 꼭 필요한 서민금융 지원을 위해 노력해야 한다"고 강조했다.
이어서 이 원장은 "현장 전문가의 의견을 반영하여 취약계층을 위한 금융과 함께 금융교육, 컨설팅, 종합상담 등 자활기반을 구축하도록 힘쓰겠다"고 밝혔다. 이날 참석자들은 '정책서민금융지원에 대한 방향성'에 대하여 다양한 의견을 제시했다.
진흥원은 이날 간담회의 다양한 제언들을 바탕으로 수요자가 체감할 수 있는 실질적인 방안 마련을 위해 더욱 노력하고, 지속적으로 서민금융 현장의 폭넓은 의견을 청취할 계획이다.
"""],
["""JB금융지주는 차기 회장 후보자로 김기홍 JB자산운용 대표(사진)를 선정했다.
19일 JB금융지주 임원후보추천위원회는 최종 후보군에 대해 PT발표와 심층면접을 진행한 후, 김 대표를 최종 후보자로 선정했다.
이날 PT발표와 심층면접에선 후보자의 JB금융그룹의 성장 비전과 전문성, 리더십, 기업의 사회적 책임 등 후보자의 역량에 대해 평가했으며, 김 대표는 은행을 비롯 보험사, 자산운용사 등 금융권 임원 경험을 바탕으로 금융 전반에 대한 전문적인 지식과 넓은 식견을 갖추고 있다는 점이 높이 평가됐다.
JB금융지주 임추위 관계자는 "김 후보자가 20년 이상 금융산업에 종사한 경험을 바탕으로 금융에 대한 전문적인 식견 뿐 만 아니라 리더십과 소통능력도 탁월하다"며 "급변하는 금융환경에 대응하고 계열사 간 시너지 창출을 통해 기업가치를 극대화하는 등 JB금융그룹을 최고의 소매전문 금융그룹으로 발전시킬 적임자"라고 밝혔다. 이에 따라 김 내정자는 내년 3월 정기주주총회와 이사회를 거쳐 대표이사 회장으로 선임 될 예정이다.
"""],
["""1800만 근로자의 2018년 귀속 근로소득에 대한 연말정산 신고기간이 한 달여 앞으로 다가왔다.
올해 연말정산에는 중소기업 취업 청년에 대한 소득세 감면이 확대되고 도서·공연비 지출액에 대한 신용카드 사용액에 소득공제가 적용되는 등 새로운 기준이 적용되기 때문에 바뀐 공제 기준을 꼼꼼히 챙기는 것이 중요하다.
국세청은 올해 근로소득이 발생한 근로자는 내년 2월분 급여를 지급받을 때까지 연말정산을 신고해야 한다고 20일 밝혔다.
◇올해부터 달라지는 주요 공제 항목
올해 연말정산부터는 중소기업 취업 청년에 대한 소득세 감면을 받을 수 있는 대상 연령이 기존 29세에서 34세로 확대된다. 감면율도 70%에서 90%로 확대되고 감면 적용기간도 3년에서 5년으로 확대된다.
총급여액 7000만원 이하 근로자는 도서·공연비를 신용카드로 결제한 경우 해당 비용을 최대 100만원까지 추가 소득공제 받을 수 있다. 올 7월1일 이후 도서공연비로 지출한 금액의 소득공제율 30%가 적용되기 때문이다.
건강보험 산정특례 대상자로 등록된 부양가족을 위해 지출한 의료비는 기존 700만원 한도가 폐지되고 올해부터 전액공제를 받을 수 있게 됐다.
총급여액이 5500만원이거나 종합소득금액이 4000만원 초과 근로자의 경우 월세액 세액공제율이 10%에서 12%로 인상된다. 월세액 세액공제 한도는 750만원이며 임대차 계약서상 주소지와 계약기간 등 내역을 정확히 기재해야 공제를 받을 수 있다.
임차보증금 3억원 이하의 주택 임차보증금 반환 보증 보험료도 올해 연말정산부터 보험료 세액공제를 받을 수 있으며, 생산직 근로자의 초과근로수당 비과세 적용 시 기준이 되는 월정액 급여액은 150만원 이하에서 190만원 이하로 상향된다.
6세 이하 자녀 세액공제는 아동수당 지급에 따라 올해부터 폐지된다. 올 연말정산부터는 종교단체가 종교인에게 지급한 소득도 신고대상에 포함된다."""]
]
- 한글 자연어 처리 클래스 적용
In [3]:
kkma = Kkma()
In [4]:
# kkma.sentences(data[0][0])
# sentences = [kkma.sentences(da[0]) for da in data]
# word_list = [[kkma.nouns(w) for w in sentence] for sentence in sentences]
# word_list
In [5]:
# word_list = []
# sentences = []
# for da in data:
# # print(da)
# sentences.append(kkma.sentences(da[0]))
# for s in sentences:
# for w in s:
# for t in kkma.nouns(w):
# if len(t) >= 2:
# word_list.append(t)
# # word_list.append(kkma.nouns(w))
- word2vec으로 학습하기 위한 데이터 전처리
In [6]:
sentences = []
list_vec = []
for da in data:
# print(da)
sentences.append(kkma.sentences(da[0]))
for s in sentences:
for w in s:
list_vec.append(kkma.nouns(w))
In [7]:
word_list = []
for l in list_vec:
empty_vec = []
for w in l:
if len(w)>=2:
empty_vec.append(w)
word_list.append(empty_vec)
- modeling
In [8]:
# word_list
# word_list_tot = word_list[0]
# for i in range(len(word_list)-1):
# word_list_tot = word_list_tot + word_list[i+1]
# word_list_tot
# sg : {0, 1}, optional
# Training algorithm: 1 for skip-gram; otherwise CBOW.
# size : embedding 차원
embedding_model = Word2Vec(word_list, size=100, window = 5, min_count=2, workers=3, iter=1000, sg=1, sample=1e-3)
In [9]:
# word_count = ["증권"]
# word_top = embedding_model.wv.most_similar(positive=["선임", "대표", "증권"], topn=10)
# word_top
# [w[0] for w in word_top]
# embedding_model.wv.distances("증권")
# embedding_model.wv.vectors.shape
- 벡터화된 단어들로 Kmean Clustering
In [10]:
from sklearn.cluster import KMeans
word_vectors = embedding_model.wv.syn0 # 어휘의 feature vector
num_clusters = int(word_vectors.shape[0]/50) # 어휘 크기의 1/5나 평균 5단어
print(num_clusters)
num_clusters = int(num_clusters)
In [11]:
kmeans_clustering = KMeans(n_clusters=num_clusters)
idx = kmeans_clustering.fit_predict(word_vectors)
idx = list(idx)
names = embedding_model.wv.index2word
word_centroid_map = {names[i]: idx[i] for i in range(len(names))}
- 결과 확인
In [12]:
for c in range(num_clusters):
# 클러스터 번호를 출력
print("\ncluster {}".format(c))
words = []
cluster_values = list(word_centroid_map.values())
for i in range(len(cluster_values)):
if (cluster_values[i] == c):
words.append(list(word_centroid_map.keys())[i])
print(words)
- word2vec을 100차원으로 했기 때문에 시각화를 위해서 2차원으로 축소,
- 축소할 때 관계를 유지하기 위해 t-SNE로 transform
In [13]:
from sklearn.manifold import TSNE
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
import matplotlib
path_gothic = "/home/ururu/fonts/NanumGothic.ttf"
prop = fm.FontProperties(fname=path_gothic)
matplotlib.rcParams["axes.unicode_minus"] = False
In [14]:
vocab = list(embedding_model.wv.vocab)
X = embedding_model[vocab]
tsne = TSNE(n_components=2)
X_tsne = tsne.fit_transform(X)
In [15]:
import pandas as pd
df = pd.DataFrame(X_tsne, index=vocab, columns=["x", "y"])
In [16]:
df.head()
Out[16]:
In [17]:
%matplotlib inline
fig = plt.figure()
fig.set_size_inches(40, 20)
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df["x"], df["y"])
for word, pos in list(df.iterrows()):
ax.annotate(word, pos, fontsize=12, fontproperties=prop)
plt.show()

classification¶
In [18]:
# embedding_model.wv.save_word2vec_format("word2vec.txt")
vectors = embedding_model.wv.vectors
names = embedding_model.wv.index2word
- distance matrix
In [19]:
from scipy.spatial import distance_matrix
distance = distance_matrix(vectors, vectors)
distance_df = pd.DataFrame(distance, columns=names, index=names)
In [20]:
# 금융, 부동산, 보험
# distance_df.loc[vecs, :]
- Term Document Matrix
In [21]:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
In [22]:
word_data = []
for word in word_list:
for argu in word:
word_data.append(argu)
In [23]:
vec = CountVectorizer()
X = vec.fit_transform(set(word_data))
In [24]:
TDM_DF = pd.DataFrame(X.toarray(), columns=vec.get_feature_names()).T
TDM_DF = TDM_DF.sum(axis=1).to_frame()
TDM_DF.rename(columns={0:"doc1"}, inplace=True)
TDM_DF.head()
idx_bool = TDM_DF["doc1"] >= 1
TDM_DF[idx_bool] = 1
In [25]:
TDM_matrix = TDM_DF.loc[names].values
distance_df_matrix = distance_df
- labeling
In [26]:
classification_word = ["금융", "부동산", "보험", "은행", "카드", "증권"]
# wanted_word = ["금융", "부동산", "보험"]
target_matrix = distance_df.loc[classification_word,:].values
- vector inner product로 최대값을 구하여 분류
In [27]:
import numpy as np
result = np.matmul(target_matrix, TDM_matrix)
maxpool = np.argmax(result)
classification_rlt = classification_word[maxpool]
print("classification result: {}".format(classification_rlt))
In [28]:
from IPython.core.display import display, HTML
display(HTML("<style> .container{width:100% !important;}</style>"))
'Deep_Learning' 카테고리의 다른 글
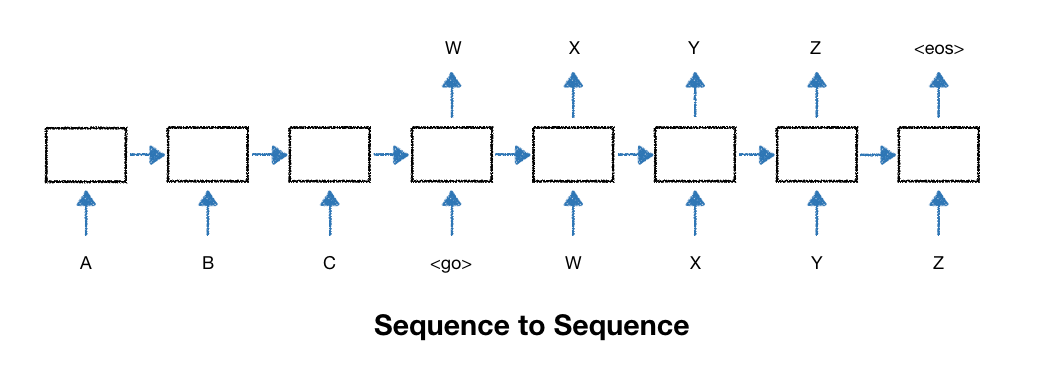
| 18.word2vec (0) | 2018.12.19 |
|---|---|
| 17.seq2seq (0) | 2018.12.19 |
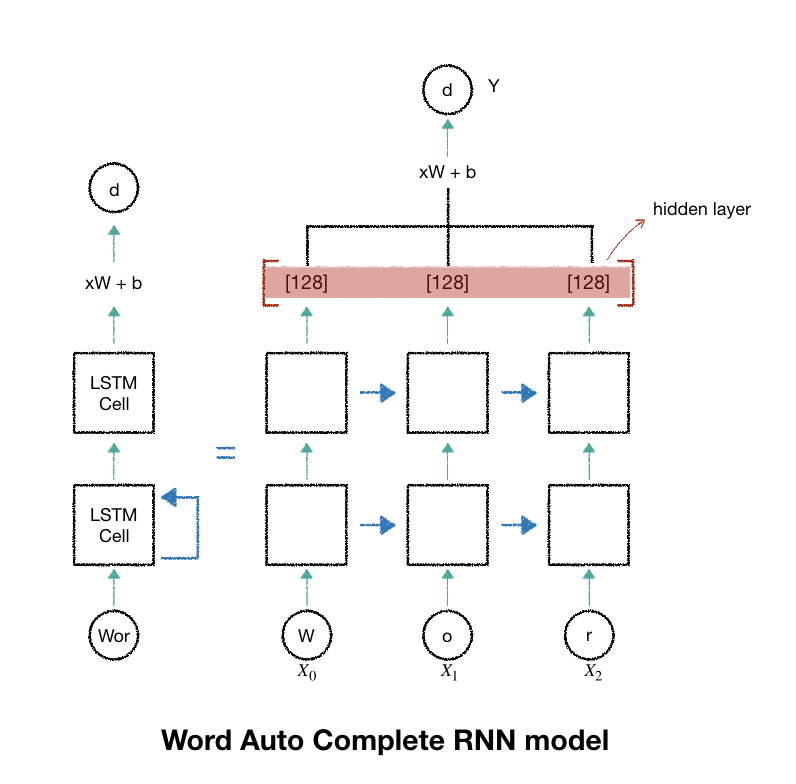
| 16.RNN_word_autoComplete (0) | 2018.12.18 |
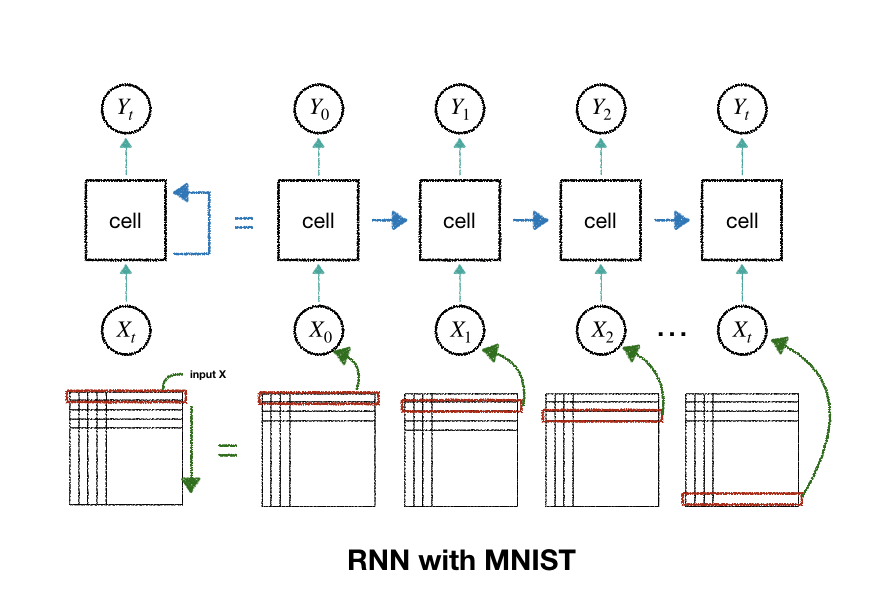
| 15.RNN_mnist (1) | 2018.12.18 |
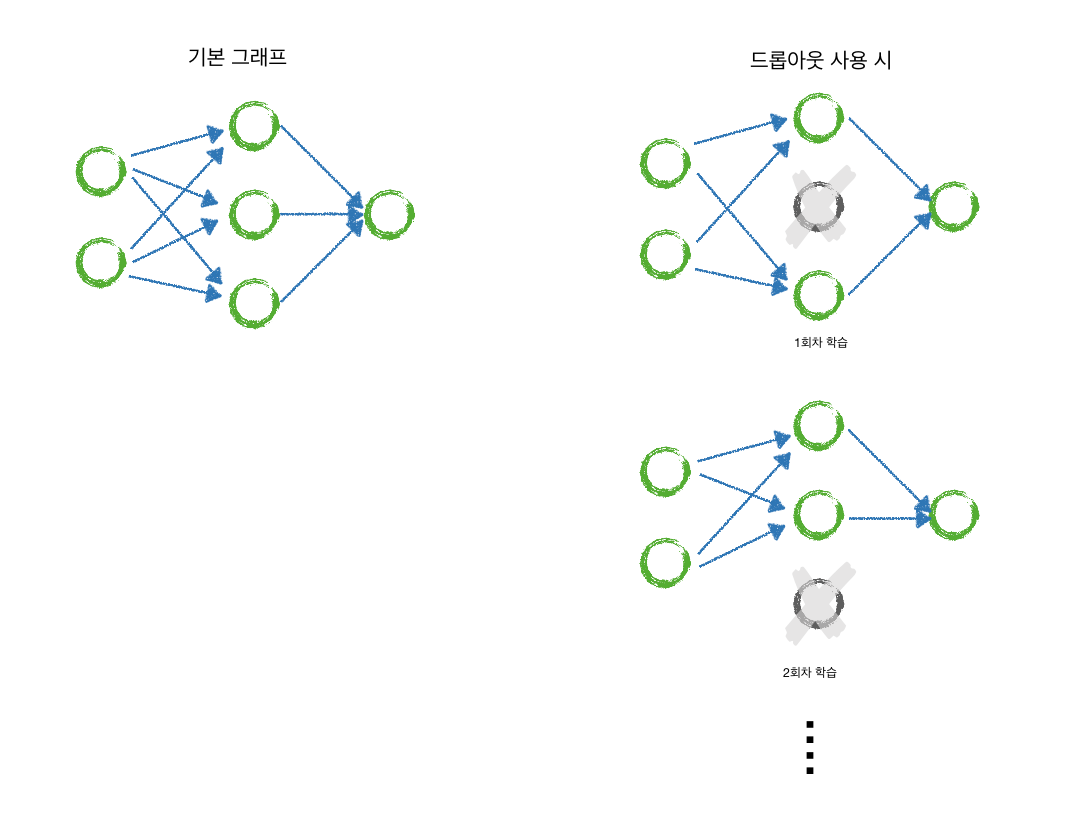
| 14.gan (0) | 2018.12.16 |