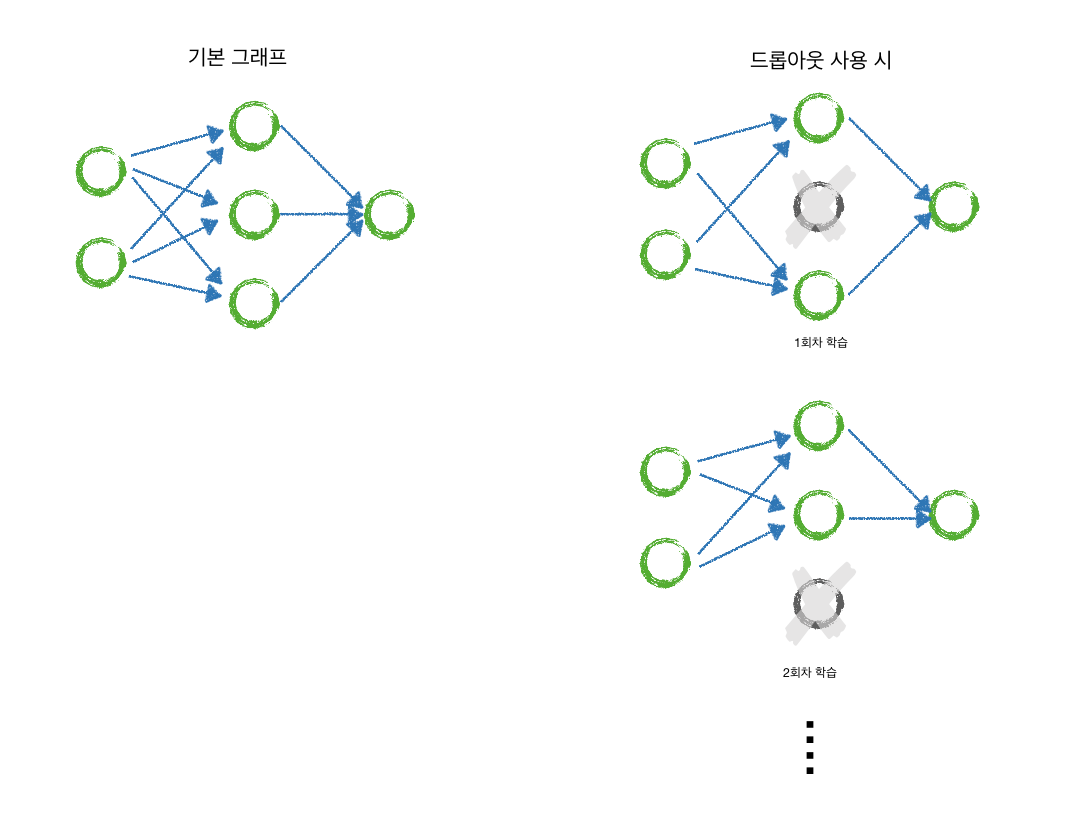
- 지정한 크기의 영역을 window라 하며, 이 window를 오른쪽, 아래쪽으로 움직이면서 hidden layer를 완성
- 몇 칸씩 움직이는 값을 stride스트라이드라 함

- 이렇게 input layer의 window를 hidden layer의 뉴런 하나로 압축할 때, convolution 계층에서는 window 크기(ex 3x3이면 9개의 가중치)만큼의 가중치와 1개의 bias이 필요함
- 이 때 window의 크기와 bias를 kernel 혹은 filter라고 하며, 이 kernel은 해당 hidden layer를 만들기 위한 모든 window에 공통으로 적용
- 기본 신경망으로 모든 뉴런을 연결하면 784개의 가중치를 찾아내야 하지만, convolution에서는 3x3개인 9개의 가중치만 찾아내면 되므로 시간이 빠름
- 알고리즘을 진행하는데 튜닝하는 파라미터를 하이퍼 파라미터라함

In [1]:
import tensorflow as tf
import pandas as pd
import numpy as np
In [4]:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
CNN 모델에서는 2차원 평면으로 구성하므로 조금 더 직관적인 형태로 구성할 수 있음.
- X의 첫번째 차원인 None은 입력 데이터 갯수
- 마지막 차원은 1, MNIST 데이터는 회색조 이미지라 색상이 한개 뿐이므로 depth=1을 사용
- 출력값인 10개의 분류와, dropout, keep_prob를 정의
In [5]:
global_step = tf.Variable(0, trainable=False, name="global_step")
X = tf.placeholder(tf.float32, shape=[None, 28, 28, 1], name="X")
Y = tf.placeholder(tf.float32, shape=[None, 10], name="Y")
keep_prob = tf.placeholder(tf.float32, name="KEEP_PROB")
첫 번째 CNN 계층을 구성
- 3x3 크기의 커널을 가진 convolution 계층을 구성
- kernel에 사용할 가중치 변수와 tensorflow가 제공하는
tf.nn.conv2d()함수를 사용

In [6]:
# 3x3x1 크기의 커널과 (1)을 가지고32개의 커널
with tf.name_scope("layer1"):
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
# 입력층 x, 첫 번째 계층의 가중치 W1, 오른쪽과 아래쪽으로 1칸 ,
# padding="SAME" -> 이미지의 가장 외곽에서 한 칸 밖으로 움직임
# strides=[1, 오른쪽, 아래쪽, 1], 양 끝은 반드시 1
# [batch_size, image_rows, image_cols, number_of_colors]
L1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1 ,1], padding="SAME")
L1 = tf.nn.relu(L1)
# [batch_size, images_width, images_height, number_of_colors]
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")

In [7]:
with tf.name_scope("layer2"):
# 3x3x1 -- 32개를 받아 64개로 convolution 계층 만듬
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding="SAME")
L2 = tf.nn.relu(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")

In [8]:
with tf.name_scope("layer3"):
# 7x7x64크기의 1차원 계층을 만들고 중간단계인 256개의 뉴런으로 연결하는 신경망을 만들어줌
# fully connected layer
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
L3 = tf.reshape(L2, [-1, 7 * 7 *64])
L3 = tf.matmul(L3, W3)
L3 = tf.nn.relu(L3)
L3 = tf.nn.dropout(L3, keep_prob)
In [9]:
with tf.name_scope("layer4"):
W4 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L3, W4)
In [10]:
with tf.name_scope("cost"):
cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
opt = tf.train.AdamOptimizer(0.001).minimize(cost)
# opt = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
tf.summary.scalar("cost", cost)
In [11]:
# batch_xs.reshape(-1, 28, 28, 1)
# mnist.test.images.reshape(-1, 28, 28, 1)
In [12]:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("./logs/mnist_cnn", sess.graph)
cost_epoch = []
modeling¶
In [13]:
%%time
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(15):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
_, cost_val = sess.run([opt, cost], feed_dict={X: batch_xs,
Y: batch_ys,
keep_prob: 0.8})
total_cost += cost_val
cost_epoch.append(total_cost)
summary = sess.run(merged, feed_dict={X:batch_xs, Y: batch_ys, keep_prob:0.8})
writer.add_summary(summary, global_step=sess.run(global_step))
print("Epoch:", "%4d" % (epoch+1),
"Avg.Cost:", "%.4f" % (total_cost / total_batch))
print("optimization completed")
costfunction¶
In [14]:
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 8))
plt.plot(cost_epoch, "g")
plt.title("cost")
plt.show()

tensorgrapth¶
In [15]:
## jptensor.py 를 워킹디렉토리에 import
import jptensor as jp
tf_graph = tf.get_default_graph().as_graph_def()
jp.show_graph(tf_graph)
In [16]:
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print("accuracy %.4f" % (sess.run(accuracy, feed_dict={
X:mnist.test.images.reshape(-1, 28, 28, 1),
Y:mnist.test.labels,
keep_prob: 1
})))
labels¶
In [17]:
%matplotlib inline
labels = sess.run(model, feed_dict={X: mnist.test.images.reshape(-1, 28, 28, 1),
Y: mnist.test.labels,
keep_prob: 1})
fig = plt.figure()
for i in range(10):
# (2, 5)의 그래프, i + 1번째 숫자 이미지 출력
subplot = fig.add_subplot(2, 5, i+1)
# x, y축 눈금 제거
subplot.set_xticks([])
subplot.set_yticks([])
# 출력한 이미지 위에 예측한 숫자를 출력
# np.argmax와 tf.argmax는 같은 기능
# 결과값인 labels의 i번째 요소가 one-hot encoding으로 되어 있으므로
# 해당 배열에서 가장 높은 값을 가진 인덱스를 예측한 숫자로 출력
subplot.set_title("%d" % np.argmax(labels[i]))
# 1차원 배열로 되어 있는 i번째 이미지 데이터를
# 28 x 28형태의 2차원 배열로 변환
subplot.imshow(mnist.test.images[i].reshape(28, 28))
plt.show()

In [18]:
from IPython.core.display import display, HTML
display(HTML("<style> .container{width:100% !important;}</style>"))
'Deep_Learning' 카테고리의 다른 글
| 14.gan (0) | 2018.12.16 |
|---|---|
| 13.auto-encoder (0) | 2018.12.15 |
| 11.mnist_matplotlib_dropout_tensorgraph (0) | 2018.12.10 |
| 10.mnist_dropout (0) | 2018.12.10 |
| 00.write_csv (0) | 2018.12.09 |